FlowSense
 FlowSense is the natural language interface (NLI) that assists with dataflow diagram editing in VisFlow.
See the following VAST fast forward video for a short summary of the NLI.
FlowSense is the natural language interface (NLI) that assists with dataflow diagram editing in VisFlow.
See the following VAST fast forward video for a short summary of the NLI.
To use FlowSense, right click on the canvas or a diagram element and choose
. You may also press the shortcut ⇧ +S to open the FlowSense input.Examples
The input provided to FlowSense must be a natural language sentence that specifies a diagram editing operation. The following list shows some example inputs in the context of the sample car/gdp dataset.
Note
You must load the sample dataset before trying the other natural language inputs. You may load the dataset by the first input below: load car dataset. The system cannot identify the dataset specific elements such as table column names without a loaded dataset in the dataflow.
- load car dataset
- draw a plot
- show the cars
- create a scatterplot of mpg and cylinders
- show a parallel coordinates for all the columns
- show GDP(Billion US$) series over year grouped by Country Code *gdp dataset
- visualize the distribution of mpg
- show the selection in a scatterplot
- find the cars with maximum mpg
- filter cars by mpg
- find cars with mpg between 15 and 20
- sample 5 percent of the cars
- highlight the selected data in a histogram
- set opacity to 0.5
- encode mpg by red green color scale
- map horsepower to size from 1 to 5
- merge the data from node-1 with node-2
- find the cars with a same name from node-1
- link the cars by name from node-1
- remove node-1
- connect the scatterplot with the table
- disconnect node-1 from node-2
Functionality
FlowSense facilitates diagram editing and its main goal is to facilitate node and edge creation along with visual property editing. But it may also perform some helper tasks such as loading datasets, adjust diagram layout, etc.
The functionality FlowSense performs can be categorized into the following FlowSense functions:
| Function | Sample Query | Description |
|---|---|---|
| Visualization | show a scatterplot of mpg and horsepower | Create a visualization to present the data |
| Visual Encoding | encode mpg by red green color scale | Map data attributes to visual properties |
| Attribute Filtering | find the cars with mpg between 15 and 20 | Filter data items by attribute values |
| Subset Manipulation | merge the data from node-1 with node-2 | Refine and identify subsets of interest |
| Highlighting | highlight the selected cars in a histogram | View the characteristics of one subset among its superset or another subset |
| Linking | find the cars with a same name from node-1 | Perform linking between two tables |
| Edge Editing | connect/disconnect the scatterplot and node-2 | Add/remove diagram edges |
| Node Editing | remove node-1 | Rremove diagram node |
| Data Loading | load car dataset | Create a data source to load a given dataset |
| Layout Adjustment | adjust the diagram layout | Automatcially adjust dataflow diagram layout |
Special Utterances
Some words in the natural language input has special meanings in the dataflow context. FlowSense identifies these words and explicitly tags them in the user interface. Four types of tags are identified: data column, node type, node label, and dataset.
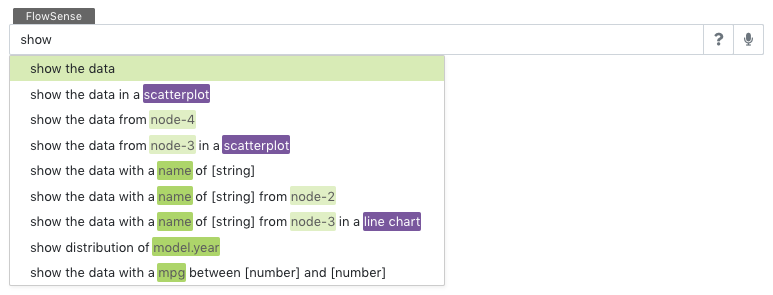
When a query is being typed, auto completion helps find those special utterances that are commonly used in natural language queries, as show in the following figure:

Pressing the ↑ ↓ and tab keys to select between the suggested words.
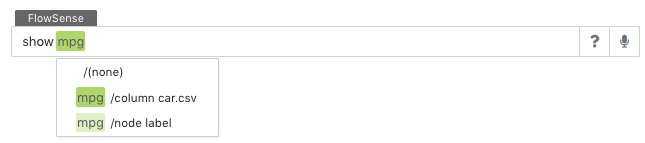
Under very rare circumstances, if a word has ambiguous meaning and can be tagged as different types of special utterances, click on the tagged word to manually select an intended tag:
Query Syntax
A natural language query consists of the following essential parts:
Function Type
A verb should be given to specify which type of FlowSense function to perform.
Example verbs include show, draw, filter, highlight, set, etc.
Among those, show, draw perform visualization functionality,
filter performs attribute filtering,
highlight performs selection highlighting,
and set assigns visual properties.
Function Options
The query may include additional descriptors to describe how a FlowSense function should be performed. For example, "show mpg and cylinders" decribes two columns to visualize, which are parsed as options to be configured on the created visualization node. "encode mpg by red green color scale" describes the creation of a Visual Editor
. Additionally, it indicates that the visual editor should be in Encoding Mode, and map the mpg Column to a red green color scale.Subset Condition
The query may includes a condition to operate on a subset of the data.
A condition may describe an attribute filtering requirement. For example, "cars with mpg between 15 and 20" finds a subset of cars with a condition on the mpg values and implies the usage of an Attribute Filter
. FlowSense automatically determines if a filter should be created for a condition.A condition may also describe interactive selection. For example, "selected cars" indicates that the query should be performed on output of the Selection Port of a visualization node. In this case the dataflow diagram is extended from the selection port.
Target Node
When the query operates on a subset, it may optionally indicate a target node where the subset should be sent to. For example, "in a scatterplot" indicates that the subset should be visualized in a Scatterplot
.When no target node is explicitly given, FlowSense automatically determines if a target node should be created. For example, FlowSense creates a plot upon "show the data" or "show mpg" and chooses a best visualization type depending on the number of columns to show.
Source Node
A query may optoinally specify a source node to indicate where the subset to operate on comes from. For example, "show the selected cars from plot-1" describes that the data to show comes from the Selection Port of plot-1. Here plot-1 is a node label that refers to a visualization node in the dataflow diagram.
Auto Completion
FlowSense provides suggestions on partially completed queries automatically. You may also use the suggestion button
on the right of the FlowSense input box for suggested queries.Voice Input
Press the voice button
to enable voice input to the FlowSense input box. When voice is enabled, speak to the microphone and the query will be recorded into the input box. Press enter to submit the query.